In partnership with

|
BUILDER HUSTLE
AI · TECH · STARTUPS
|
|
|
In This Issue
|
|
🔀 OpenRouter's Fusion API Beats Fable 5 Performance at Half the Cost
|
|
🇨🇳 US Banned Fable 5. China Released GLM 5.2. It Hit #1 the Next Day.
|
|
🔊 This 66M Parameter Model Runs on a Raspberry Pi and Beats ElevenLabs on Speed
|
|
✂️ This AI Agent Looks for Reasons Not to Write Code. It Ships 80% Less of It.
|
|
|
🔀 OPENROUTER · FUSION API · MULTI-MODEL
|
|
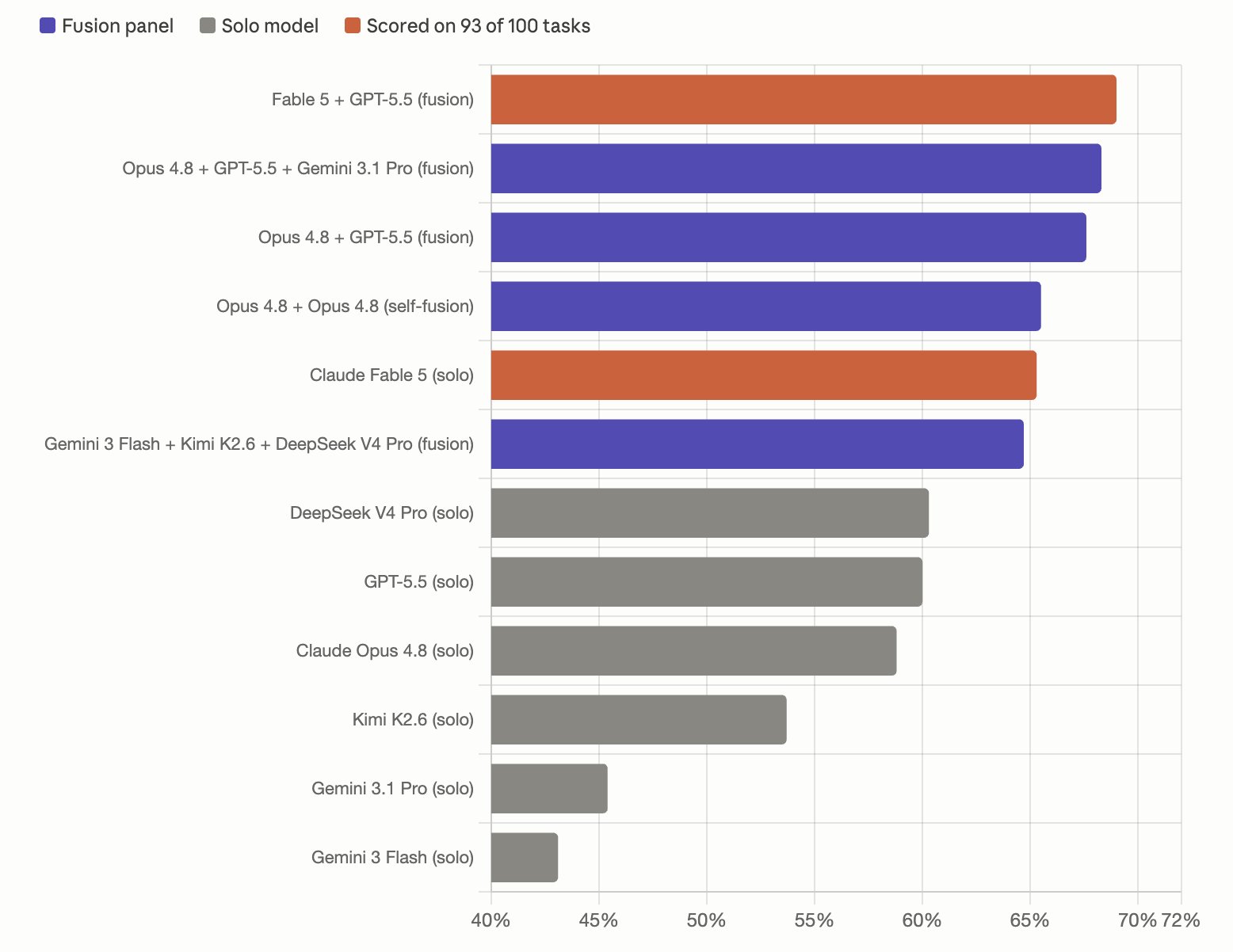
OpenRouter's Fusion API Runs Your Prompt Through a Panel of Models, a Judge, and a Synthesizer. It Comes Within 1% of Fable 5 at Half the Cost.
|
|
|
OpenRouter launched Fusion, a compound intelligence API that fans your prompt out to multiple models in parallel, each with web search and bash tools. A judge model then analyses all responses for consensus, contradictions, unique insights, and blind spots. A synthesizer produces the final answer. Tested on 100 hard research tasks from Perplexity's DRACO benchmark, a budget panel of Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro outperformed solo GPT-5.5 and Opus 4.8, and came within 1% of Fable 5 performance at roughly half the cost. Roughly 75% of the gain comes from intelligent synthesis, 25% from model diversity.
|
|
📌 Runs server-side. Call it like any model. Supports custom panels and tool-calling integration out of the box.
|
|
⚡ The synthesis step does most of the work. Three cheap models with a smart judge beat one expensive model on hard research tasks.
|
|
🔭 If you're paying Fable 5 prices for research or reasoning tasks, Fusion is worth testing today. The cost difference on volume will compound fast.
|
|
|
Read the full benchmark breakdown →
|
|
|
🇨🇳 GLM 5.2 · AI REGULATION · OPEN SOURCE
|
|
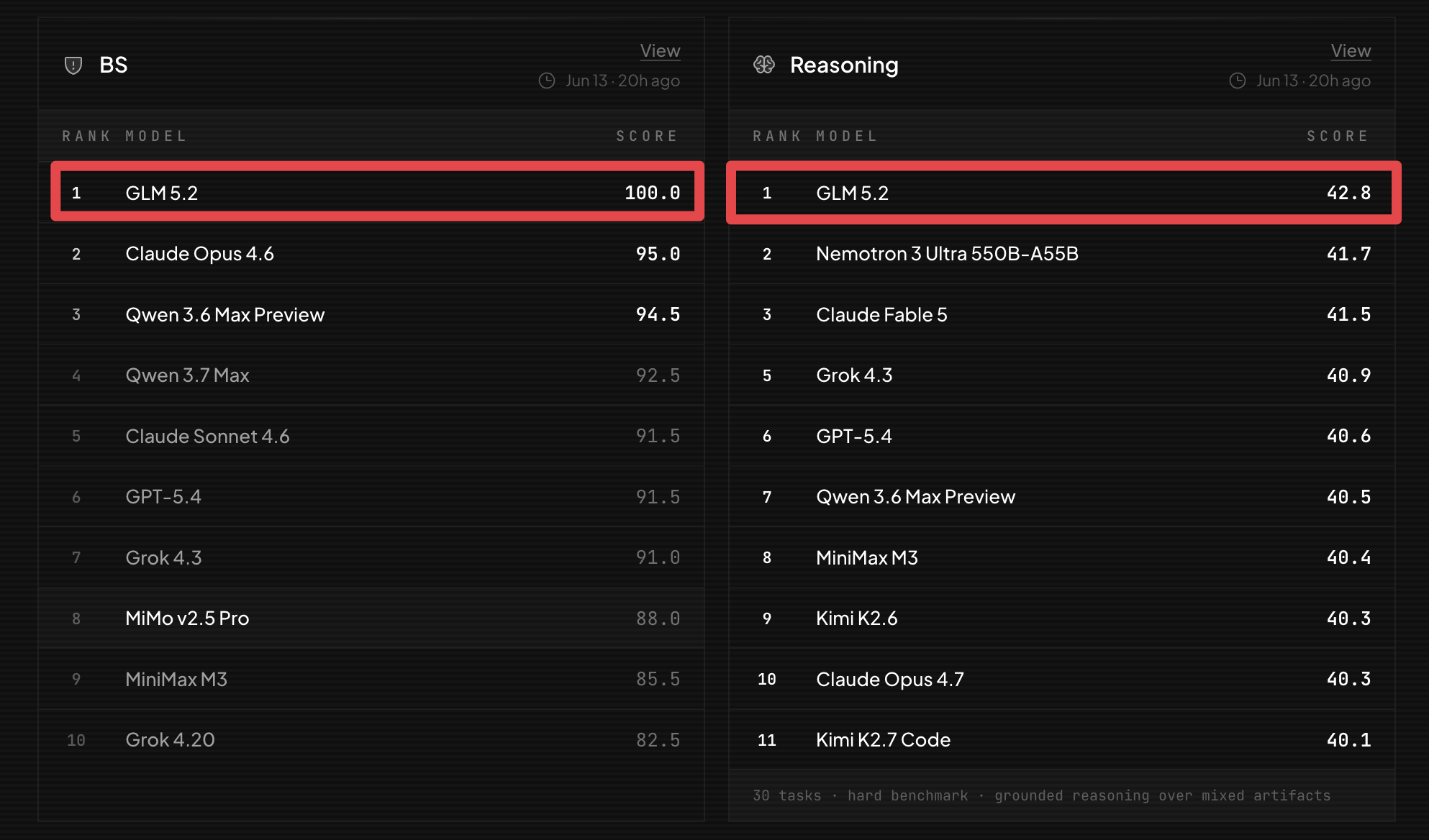
US Bans Fable 5. China Ships GLM 5.2 the Next Day. It Hits #1 on Two Leaderboards. At a Tenth of the Cost.
|
|
|
The timeline was pointed: day one, the US banned Claude Fable 5 worldwide. Day two, China released GLM 5.2. Day three, GLM 5.2 hit number one on Bridgebench's vibe-coding leaderboard with a perfect score of 100.0 and topped the reasoning leaderboard at 42.8, both beating Fable 5. It runs at 300 tokens per second and costs roughly one tenth of Fable's price. The post's closing line landed hard: "You cannot export control your way out of an open source race."
|
|
📌 Bridgebench is a vibe-coding benchmark, not a general capability eval. Take the #1 claim in that context, not as a global ranking.
|
|
⚠️ 300 tokens per second at a tenth of Fable's cost is the real headline. Speed and price matter more than benchmark rankings for most production use cases.
|
|
🔭 Every export control on a US frontier model accelerates open-source adoption globally. The gap between "restricted" and "available" is where Chinese labs win market share.
|
|
|
See the leaderboard post →
|
|
200+ Claude Prompts Top Professionals Actually Use at Work
Claude can be your analyst, editor, and strategist.
But most professionals are using it to fix grammar.
These 200+ Claude prompts take it from grammar tool to your most powerful AI work assistant.
200+ ready-to-use Claude prompts to get real work done in minutes — researched, tested, and used by professionals at Google, Microsoft, and NASA
Superhuman AI newsletter (4 min daily) so you keep learning new AI tools and skills to stay ahead in your career — the prompts are just the beginning
|
🔊 SUPERTONIC · LOCAL TTS · OPEN SOURCE
|
|
A 66M Parameter TTS Model Runs on a Raspberry Pi, Hits 167x Real-Time Speed, and Beats ElevenLabs Flash. It's Free.
|
|
Supertonic is a fully local, MIT-licensed text-to-speech model with 66 million parameters. On an M4 Pro it runs at 167 times real-time speed and processes 1,263 characters per second, compared to ElevenLabs Flash at 287. It runs on a Raspberry Pi, works on e-readers in airplane mode, handles currency, dates, phone numbers, and technical units correctly out of the box, supports 11 platforms and 5 languages, and ships with a Chrome extension that converts any webpage to audio instantly.
|
|
📌 MIT licensed. Use it in commercial products today. No API costs, no usage limits, no vendor dependency.
|
|
⚡ Correct handling of currency, dates, and technical units is where most TTS models still fail. Supertonic gets these right by default.
|
|
🔭 If you're paying ElevenLabs for high-volume TTS in a product, run the numbers on Supertonic at your current usage. The savings at scale are not marginal.
|
|
|
View on GitHub →
|
|
|
✂️ PONYTAIL · AI AGENTS · LEAN CODE
|
|
This AI Agent Is Forced to Look for Reasons Not to Write Code Before It Writes Any. It Produces 80% Less. Ships 3x Faster.
|
|
|
Ponytail is an AI coding agent built out of frustration with verbose AI output. Named after the senior engineer archetype who looks at 50 lines and replaces them with one clean line, the agent is forced to search for reasons not to write code before it writes anything. The claimed results: 80 to 94% less code generated, 47 to 77% cheaper, and 3 to 6 times faster than standard AI coding agents.
|
|
📌 The core pattern is a pre-code skepticism step. Before any generation, the agent audits whether code is actually needed. That single constraint changes the output dramatically.
|
|
⚡ 47 to 77% cheaper means fewer tokens consumed. On high-volume agentic pipelines that cost reduction compounds across every run.
|
|
🔭 The "skeptic first" agent pattern is replicable in any system prompt. If Ponytail does nothing else, it proves the pattern works. That alone is worth stealing.
|
|
|
Details here →
|
|
Stay sharp,
Builder Hustle

